
How to make AGI reliably safe in a year

It seems impossible. Won’t it take years or decades to develop safe AI? Not to mention the time it takes to deploy it. I hope you will read on. My aim is to convince you that there is enough theory already developed that there is a possibility for a strong team to make it happen.
First, let us define what dangers we need to be safe from.
Types of AI danger
The Basilisk
Perhaps the scariest danger is that of an AGI or gang of AGIs who have developed an intelligence far beyond ours. Perhaps they find us insignificant or an irritant. Or perhaps they are full of malice. There is no shortage of stories about how this might turn out, and they aren’t good.
The rogue human
Almost certainly, there are, as you read this, a handful of people who are trying to create an AI that will protect and support only them and their protected clients at all costs. If they are able to get this before anyone else, they may be hard to stop.
A rogue nation
I know several AGI researchers, including myself who have been contacted by Chinese investors with bitcoin. It’s real.
Apathy
Even if AI never improves beyond today, it is inevitable that corporations must replace employees with automation in order to remain competitive thus driving an apocalyptic spiral of economic breakdown and knee-jerk legislation.
What we mean by AGI
The following working definition is taken from Wikipedia but made more precise.
An artificial general intelligence has a store of represented knowledge. It can reason over that knowledge to plan actions and to infer new knowledge from current knowledge. It can deeply (in the sense of ‘deep learning’) interpret arbitrary, modeled input streams to gain new knowledge. And it can use arbitrary output streams to interact in the world. It can integrate all these skills towards goals. Example input/output streams would be video, robot control or natural language communication streams.
There are two variables that can determine the level of intelligence here: 1. The completeness of the knowledge representation system — can it represent any knowledge? And 2. the completeness of the reasoning system — can it do any valid reasoning. If those two are complete, the intelligence is maximal. That is, it can know anything, and it is capable of learning, inferring and planning anything.
Knowledge Store + Reasoning
In the past, AIs have had limited domain knowledge stores and hard-coded logic. The problem was that no one knew how to make a general purpose knowledge store. Nor did they know how to make reasoning that could handle counter-factual logic and that also had a notion of linearity built in.
The solution has been to make a neural network try all combinations at once. So the knowledge and reasoning power are in there somewhere but it still isn’t clear how.
CIM, Causal Inference Models (pronounced sim), as pointed out by Judea Pearl and others, solve these problems. That means that a CIM could be used as the output of a program that analyzes Deep Learning models and expresses how they work.
However, the CIMs themselves can be directly worked on. They are efficient as they need not consider every possible variable, most of which are not relevant. This is a new type of AI that can have highly complex models yet run on a cell phone’s CPUs.
Most importantly, the models can be human readable text files.
For examples or demos please contact us.
Proteus: The Transparency Code
Our modeling language Proteus, is a CIM language. It can be used to model anything from atoms to galaxies to toothpaste to democracies and their legal systems. As stated above, Proteus files could be the output of a program that explicates DL models. But it is better to use it to create the models and use them without DL in most cases. DL may still be useful for cases such as vision or driving.
Proteus files are human readable and are surprisingly understandable.
The code is open source: see https://theSlipstream.com
Decentralization vs small rogues
Even with transparent models, there is the possibility of rogue individuals attempting to use AI to gain control before others succeed. By having an AI that is useful for everyday things like getting information or meeting new people it can be on all our devices with the idea of protecting the device and user. The details of this are spelled out else where, but it means that, with no centralized AI, no single node or even group of nodes will be able to gain control. Your phone will protect you and isolate any rogue nodes.
Nodes use peer-to-peer methods or exchange knowledge to keep the best knowledge available to the whole ecosystem.
Peer distributions vs powerful rogues
Even with the above architecture, there is a risk that powerful entities will attempt to control the knowledge base. For example, a company may try to get models that suggest smoking may not cause cancer into the knowledge base.
The Linux operating system deals with similar problems by encouraging people or groups to make different “distros’ of Linux.
Similarly, controlling a special interest narrative can be made very difficult by encouraging people to create and distribute their own version of the knowledge base. Since nodes regularly exchange and compare information, any distributions not controlled by a rogue entity will notice the misinformation and be loud about it. The nodes validate information based on CIM constraints, not on popularity.
The Slipstream vs Apathy
Another type of danger that AI can present is in the form of companies being forced to replace humans with automation causing a economic / legislative spiral. Slipstream nodes can help you get or coordinate resources. By using automation to augment rather than replace humans, the AI can help humans design a system that maximizes freedom by using abundance instead of scarcity to drive the “invisible hand”.
Slipstream Architecture at start of 2023
This diagram represents the architecture of a Slipstream node. The nodes coordinate in the decentralized, distributed way suggested above. Notice the green knowledge store / engine. This represents the knowledge-store and reasoning engine described as AGI above. Also, note the arbitrary input and output streams that can be connected or disconnected as needed to update the knowledge base or to produce actions or the answers to queries. The format of the streams is determined by the internal models. So a new model can empower a new type of stream.
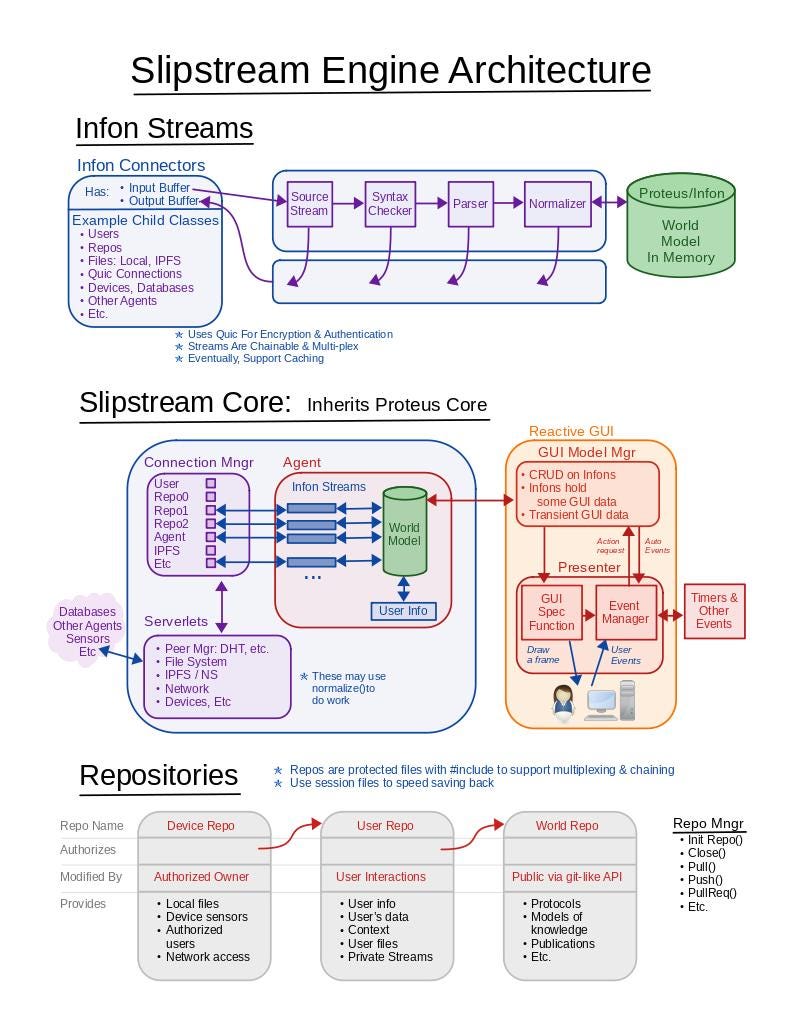
The Repositories are the Proteus knowledge bases. The only parts of this that are not completed are some of the “serverlets” in the pink box, some GUI details and the repositories. The serverlets that are not complete are those that do the decentralized distribution. In addition we need to finish porting the software to more platforms.
How to finish it in a year
With the code essentially done, the next steps are largely social. We need to start a wikipedia-like movement whereby people create models of whatever they are interested in. The first set of models, which will be highly curated, will provide a foundation for the really complex models that can facilitate things like personalized medicine and AI Lawyers. It is these foundational models, and the beginning of mass use of the system that can be done in a year.
This year is important as if we can generate the ecosystem before anyone can hijack the system then hijacking it later will be too hard to do and easy to fix.
We have a fun plan for doing this and would love to discuss it!