
Trust and Identity on The Slipstream
Using models to prevent Sybil Attacks and Identity Theft in Web3

The Slipstream is a distributed, truly decentralized, AI enhanced user agent that can make using Web3 or similar technologies extremely easy and safe. One of the driving ideas behind The Slipstream is that sometimes we humans do things for people without the expectation of something in return. Just because. We do this for our children or other family members and when the need arises we often do it for strangers. This is the idea of having compassion in an environment of abundance.
But we don’t want to be scammed. Perhaps in the process of doing what you enjoy you (or, in the near future, your robots) are making things that others would enjoy and you advertise it online. You don’t want to worry about a bot pretending to be human and gathering free things to sell for a profit (Sybil attacks). Conversely, if you have built up a reputation and perhaps a group of people who would follow you into a project — maybe you make films — you do not want to worry that someone online will pretend to be you in order to co-opt your reputation.
The flip-side of security issues such as trust and identity protection is privacy. Many solutions to one of these issues comes at a cost to the other. While dystopian solutions such as a government database of everyone, how to identify them and what their social score is might (or might not) provide some security, it does so at the expense of privacy. If done correctly, we can maximize both security and privacy.
Let us look at how Slipstream models can provide robust security while respecting privacy.
Diverse Solutions
Before jumping in to the details, it is important to make the point that The Slipstream is open and built on a very flexible protocol. And where it makes sense, forking the code and knowledge stores are encouraged. Therefore, we can talk about how the reference implementation will operate, but in the future, other distributions will do things differently. This in itself is a form of protection because there will not be one single set of protections that bad actors will have to confront. They will never know for certain that they have handled all the cases.
From here on, when we mention The Slipstream, we are referring to the reference implementation.
Architecture of The Slipstream
To understand how The Slipstream handles security issues, we need a quick overview of how the software works.
Causal Inference Models store knowledge
Much has been written about Causal Inference Models and how they can be used to represent situations in the real world. The reference implementation of The Slipstream uses a language called Proteus to store the models. Other implementations could use a different CIM language. But as long as a Proteus model of that language is given, and in that language, a model of Proteus is given, they will be compatible. Here we shall talk about Proteus. This is a very brief overview as the details exist elsewhere.
Proteus models are contained in text files or streams. The files store knowledge while streams can be used for real-time interaction. When we say “knowledge”, we mean Information, plus a representation of the meaning of the information. If the meaning is correct and the information is accurate, the knowledge is true. The meaning of the information can be inferred from the causal structure that generated the information — thus “Causal Inference Models”. For example, the meaning of the information in a photograph is related to how light causally interacted with the subjects and then with the lenses and sensors of the camera. If we know that a particular photo is of “Bob” and in the photo Bob is swimming, then we have the knowledge that at the moment the photo was taken, Bob was swimming. Proteus models could store all the causal structures representing that. The actual photograph could be stored in Proteus, but alternatively, a Proteus model of (the meaning of) JPEG files could be used to access the information in a non-Proteus file or stream. Knowledge can be very general such as the laws of physics, or particular such as storing records of historical events, or very particular such as ‘The user is currently on the phone’.
The Proteus Engine is software that loads and manages Proteus files / streams to an in-memory knowledge-base and can infer new information as well as interact via queries, statements, and later, commands.
But how is that information controlled, routed and used? That is the job of the Slipstream Engine.
Security architecture of The Slipstream Engine
The Slipstream Engine manages a Proteus engine to do things for a human user. The suggested use is to install the app on each of your devices. As we will describe below, your devices can then cooperate to act much like a single device. Here is an architecture diagram for reference.
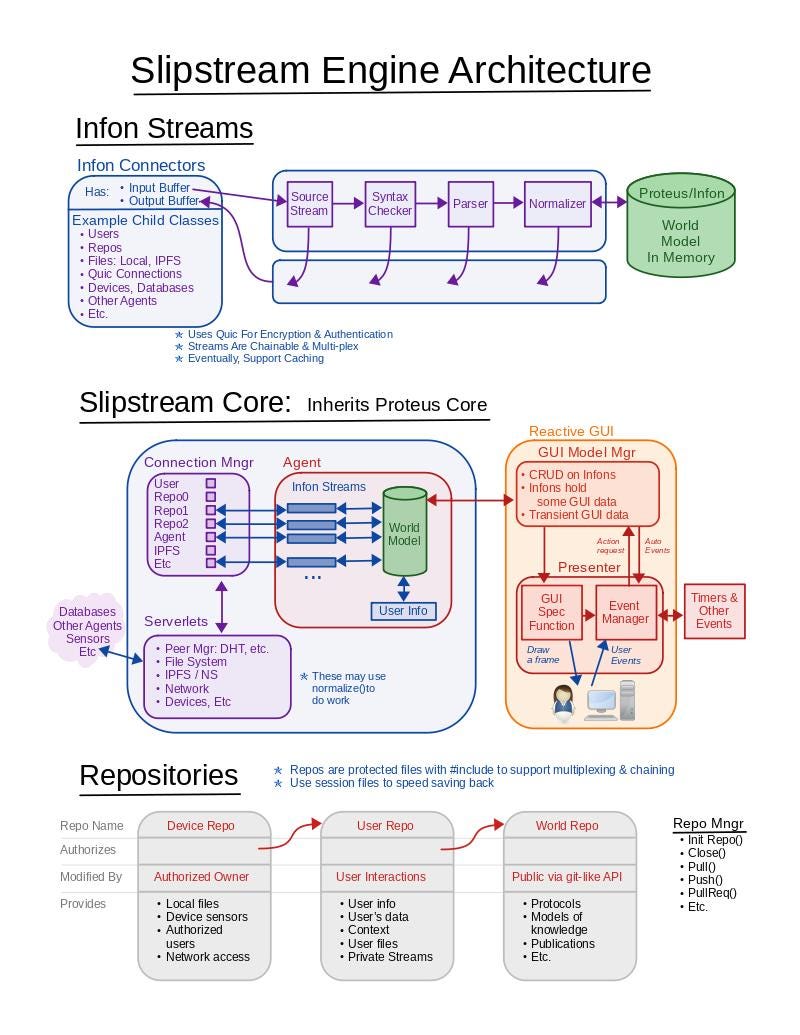
The Slipstream Core is the inner part of the engine. You can see the Proteus Engine in green. On one side the core presents a GUI with speech processing / generation and speaker identification to a validated user. On the other side it reaches out to the world. Where needed, it connects to the world (including other Slipstream nodes, such as your other devices and other trusted nodes.) via the QUIC protocol. This protocol is an IETF Web standard that is flexible, fast, and always encrypts every message. QUIC also supports the LibP2P protocols. Files are backed up or accessed on the Web3 tool Interplanetary File System (IPFS).
Identifying the User
Aside from having an inherently secure software system and secure communications, The foundation for reliable identification of remote users is for the local machine to know the user. This is a big hole in current systems. If I am logged in to my own machine it is not a guarantee that the person at the keyboard is, in fact, me. If a computer is compromised, even a remote user or bot can convince other computers that they are me. This can be somewhat mitigated by having a user re-authenticate, possibly with bio-metrics, when solid identification is needed. However, the new Web3 technique of using “stamps” from all your other accounts does not protect against Sybil attacks where bots take over many people’s machines and act as them to get stamps.
Per-device security
At the bottom of the above architecture diagram, notice there are three repositories illustrated. These consist of one or more protected Proteus files that contain specific models. The first one, the “Device Repo”, is loaded first (it is loaded through an infon stream as shown above). The device repo contains information about the device it is installed on such as the devices capabilities, whether it is Android or iOS, Slipstream permissions for local files and network assess, etc. It also contains profile information for which users are allowed to access the Slipsteam on that device and how to identify each user. Other than being identified as the user currently logged into the device, Proteus models can be made to further recognize face, fingerprints, voice patterns, etc. For example, if a speech query is made, should it require that the voice matches the user’s? If the person in front of the camera is not the user it can be made to ‘know’ that and act accordingly. To illustrate this, if the distro’s “primary command” is to get requests from the user and respond to them (it is more complex than that), then, if the person in front of the camera is not the user it may not respond.
That sounds complex, but by using the Causal Inference Models we can make it much simpler and at the same time, more secure. To illustrate this, consider the second Repo.
Per-user security
The second repository on the architecture is the “User Repo”. The user repo is securely (via QUIC / libP2P) distributed to each of the user’s devices that run the Slipstream app. It too is protected. As you can see from the diagram, it is stored separately from the main knowledge base (It is the blue rectangle labeled “User Info”). The information stored here is the information that would normally be managed by Google, Apple or Microsoft: your preferences, contacts, music, friends, chat logs (or references to them if you prefer an online service). It also tracks real-time information about you. This is the information that you currently leak to various services or the phone provider in real time, such as your location, are you currently on the phone, to who?, are you listening to music? Are you talking to a device? Are you sleeping? The Slipstream can use Web3 and other tools to provide the same services that the online eco-systems provide but it keeps your data locked tightly onto just your devices.
By storing information such as your camera feeds, device GPS, audio feed, etc, your collective devices can be quite certain that a particular person in the real-time model is, in fact, you. If you have a Dr. appointment at a certain place, and your watch and phone GPS assert that you are at the appointment and the phone camera and microphone concur, then if something is typing things into your home computer at the same time, that cannot be you. (Causal models know that things cannot have 2 locations, and that to type into a keyboard you have to be at the same location as the keyboard.) So by doing causal inference from multiple devices we can get a dramatically more accurate idea of whether an interaction in fact, with you.
Sharing identity information
The third repository is the “World Repo” or public knowledge store. This repository is stored in a IPFS based “gitTorrent” system. It is a truly distributed / decentralized git-like store based on a blockchain. Different Slipstream distributions may have slightly different knowledge stores. One may include a lot of actual data while another merely points to an on-line database that contains the data. Different distros will also have different rules for how to update the knowledge. One may require that updates to the public models may not contradict certain other models including the laws of thermodynamics. Another might allow anyone whose identity is confirmed and who is not on a blacklist to contribute. But if there is a problem later it will blacklist the user. We can try different things. But all the distributions will update each other and they can loudly point out contradictions or other problems. Group think will be harder to maintain.
In addition to confirming the identity of contributors, there are many reasons why users would want to confirm the identity of other users. For example, if they are offering their work products or to contribute money (for example, like git-coin).
To be able to confirm the identity of someone, it is important to carefully list in your user repo who you trust and how you trust your devices to contact them. Trust people that you see everyday and who have proven they are reliable, compassionate and trustworthy. Blacklist people you do not trust. This is private to you so there are no over-sized privacy issues. This can form a web of connections for verifying identity. When your slipstream app needs to verify the identity of someone, and depending on how bad the consequences are for getting it wrong, it can chart multiple paths to the computers of people that know them and can verify things, make causal inferences and even do a visual check if the user being identified consents. Only your close friends (or rather their computers) have really seen your personal information, but the person trying to establish your identity can be sure, and you can be sure, that no one is pretending to be you.
Conclusion
One way of maximizing both security and privacy, without sacrificing one for the other, is to use and maintain a web-of-trust to establish personal identity. But this can be quite complex. Web3 is already hard enough for non-technical users to understand. The Slipstream is a system designed to use personal AI to make technical tasks automatic or easy. It will do this for Web3 technologies. Here we have illustrated how the causal inference models can be used to automate a high-security distributed web-of-trust that protects privacy.